Projet Indana, GRAppA, travail de juin 2002
Retour au projet INDANA.
Objectifs
- évaluer la taille de la zone grise ;
- identifier les exemples de cette zone ;
- caractériser ces exemples.
Méthode générale proposée
- classer les exemples, suivant une mesure de confiance avec l'intuition que les exemples de la zone grise devraient se retrouver en fin de liste ;
- évaluer l'apprentissage lorsque l'on utilise les n premiers exemples de la liste, pour n allant de 1 au nombre d'exemples disponibles ;
- on espère observer un n critique où les performances chutent et rejoignent les performances d'un ordre aléatoire : dans la liste des exemples classés, la zone grise commencerait à partir de l'exemple qui a pour numéro ce n critique.
Évaluation d'un ordre sur les exemples
On parcourt la liste avec un pas donné et pour chaque valeur de n considérée, on évalue la qualité de l'apprentissage sur les n premiers exemples. Pour cela :- on découpe les n premiers exemples en deux ensembles, l'un pour l'apprentissage, l'autre pour le test ;
- on lance un C4.5 sur ces données, on récupère la précision, la sensibilité et la spécificité obtenues sur l'ensemble de test ;
- on recommence plusieurs fois et on calcule précision, sensibilité et spécificité moyennes pour cette valeur de n.
Classement des exemples
- on choisit au hasard un sous-ensemble d'exemples ;
- on découpe ce sous-ensemble en deux parties, l'une pour l'apprentissage, l'autre pour le test ;
- on lance un apprentissage C4.5 sur ces données, on récupère la précision, la sensibilité et la spécificité obtenues sur l'ensemble de test et on en déduit un score pour cet apprentissage ;
- on recommence plusieurs fois découpage et apprentissage pour obtenir le score moyen du sous-ensemble évalué ;
- on recommence plusieurs fois le tirage et l'évaluation d'un sous-ensemble d'exemples ; finalement, on moyenne le score de chaque exemple par le nombre de fois où il a été présent dans un sous-ensemble évalué ;
- on classe les exemples suivant ce score moyen, ce qui fournit un résultat semblable à celui-ci.
Protocoles des expérimentations
Données
- utilisation du fichier de données INDANA 1.2 : 2230 exemples, 107 de la classe EVENT, 2123 de la classe NO EVENT ;
- pour chaque apprentissage, les exemples de la classe minoritaire sont répliqués pour obtenir une répartition équitable entre les classes (la précision obtenue est donc systématiquement la moyenne de la sensibilité et de la spécificité).
Évaluation d'un ordre
- utilisation de C4.5 pour les différents apprentissages ;
- découpage en 70% pour l'apprentissage, 30% pour le test ;
- pour chaque ensemble d'exemples, on recommence 130 fois le découpage en apprentissage/test et la phase d'apprentissage avec C4.5 ;
- on commence par évaluer les 100 premiers exemples puis on progresse de 15 en 15.
Calcul d'un nouvel ordre
- on tire aléatoirement 4000 sous-ensembles d'exemples ;
- la taille des ensembles tirés aléatoirement est de 100 exemples ;
- dans ces ensembles, on oblige la présence d'au moins 5% d'exemples de classe EVENT (c'est la proportion naturelle) ;
- découpage en 70% pour l'apprentissage, 30% pour le test ;
- utilisation de C4.5 pour les différents apprentissages
- le score d'un ensemble d'exemples est la précision obtenue par l'apprentissage sur cet ensemble d'exemples ;
- chaque sous-ensemble est évalué 20 fois, on prend le score moyen pour noter les exemples de l'ensemble de départ.
Résultats des expérimentations
Ordres obtenus et évaluations
- ordre naturel ;
- liste des scores ;
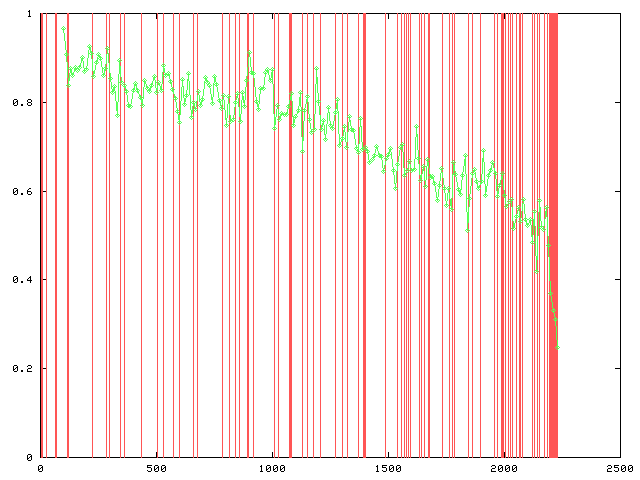
- ordre calculé, la répartition des exemples EVENT dans ce classement et un graphique montrant l'évolution de la sensibilité et l'arrivée des exemples de classe EVENT ;
- ordre calculé inversé.
{kind=link}
{kind=link}
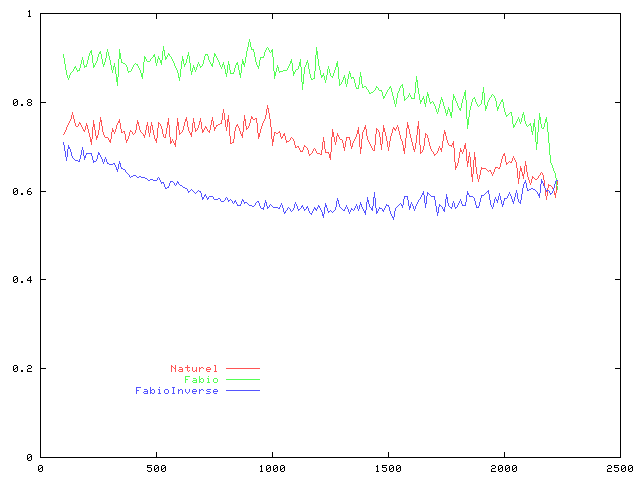
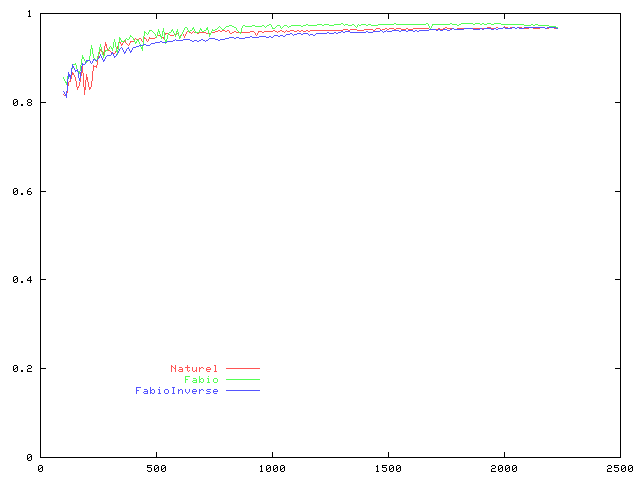
Comparaison des précisions obtenues
Comparaison des sensibilités obtenues
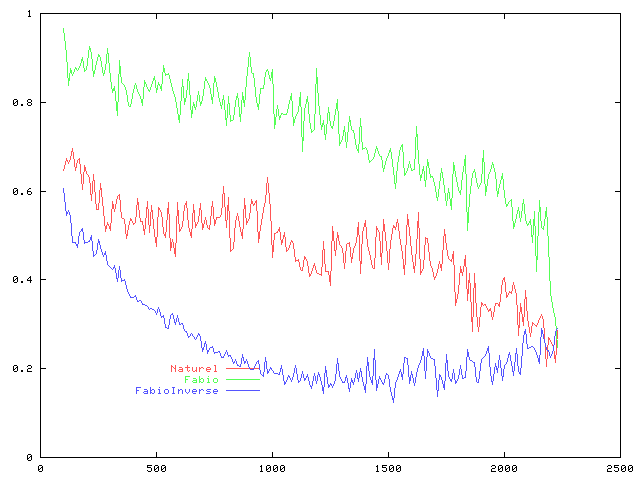
Comparaison des spécificités obtenues
Réflexions
- on observe que les deux courbes ne se rejoignent que sur le dernier point, c'est-à-dire lorsque les ensembles d'exemples considérés sont identiques et correspondent à l'échantillon complet ; du coup l'entrée dans la zone grise est difficile à détecter ;
- on observe cependant une perte de performance autour du 1500ème exemple ;
- utiliser ces 1500 premiers exemples pour apprendre et juger les règles obtenues ;
- difficulté à lisser la courbe ;
- étalement faible des scores (entre 0.82 et 0.86) ;
- on observe une forte instabilité : un exemple premier peut se retrouver 600ème à l'exécution suivante... par contre, on remarque que l'instabilité est moins forte en fin de liste, en particulier le dernier reste 2024302 dans plusieurs exécutions.
Pistes
- valider l'ordre obtenu :
- l'ordre déterminé est-il propre à notre approche ou absolu ?
- l'ordre est-il stable ? dans quelle mesure un exemple change de position d'une exécution à l'autre ?
- essayer de classer les exemples par d'autres méthodes, en observant un algorithme de boosting en particulier ;
- validation par les médecins ? peut-on confirmer des différences fondamentales entre le premier exemple de la classe EVENT dans la liste et le dernier ? entre le premier et le dernier de la classe NO EVENT ?
- caractériser les exemples de la zone grise ? apprentissage avec les premiers exemples contre les derniers ?
- visualisation de la répartition des exemples.
Retour au projet INDANA.