Bases du langage Python
Syntaxe Python, variables et types de base
Exercice 1 : valeurs et types, expressions et variables
Utiliser la console Python, pour :
- taper des nombres, des chaînes de caractères, des booléens,
- taper des opérations arithmétiques, concaténations de chaînes et expressions booléennes,
- afficher les types des expressions précédentes à l'aide de l'instruction type(),
- convertir les valeurs obtenues d'un type à l'autre avec les opérateurs str(), bool(), int() et float().
Reprendre ces questions en stockant valeurs et résultats des expressions dans des variables.
Recommencer une dernière fois l'exercice en travaillant, non plus dans la console, mais dans un éditeur de texte et en produisant les affichages avec l'instruction print.
Exercice 2 : l'instruction print
- Tester l'instruction d'affichage print de Python en affichant successivement un booléen, un nombre, une chaîne de caractères, une variable.
- Afficher trois valeurs avec une seule instruction print(). Faire apparaître un symbole de votre choix entre les différentes valeurs.
- Réaliser le même affichage mais sans passer à la ligne à la fin.
- Effectuer un passage à la ligne sans autre affichage.
- Utiliser l'instruction help() pour obtenir la documentation de print.
Exercice 3 : tuples en Python
- Définir dans une variable un tuple décrivant un restaurant à travers quatre éléments : nom, adresse, prix moyen et végétariens bienvenus ou non.
- Confirmer le type de cette variable à l'aide de l'instruction type().
- Déballer ce tuple dans quatre variables distinctes et les afficher.
- Extraire directement le troisième élément du tuple et l'afficher.
Structures de contrôle en Python
Exercice 1 : si alors sinon
- Définir une variable « température ».
- Afficher un message différent selon que la température est supérieure à 25° (« allons à la plage ») ou non (« restons à la maison »).
- En utilisant elif, afficher un message différent (« faut voir ») dans le cas où la température est comprise entre 20 et 25°.
- En plus de la variable « température », ajouter une variable booléenne indiquant si le ciel est dégagé ou non.
- Raffiner, selon ce booléen, le cas où la température est entre 20 et 25° : afficher, dans chacun des cas possibles, l'un des deux messages initiaux (plage ou maison).
- Utiliser des opérateurs booléens pour obtenir le même comportement avec un seul if ... else ....
Exercice 2 : boucle tant que et boucle pour
- Écrire une boucle while qui affiche les entiers de 1 à 10.
- Définir un intervalle à l'aide de l'instruction range et des paramètres (1,11). Stocker cet intervalle dans une variable et observer son type.
- Utiliser une boucle for pour afficher les entiers de cet intervalle.
- À l'aide de boucles for imbriquées, dessiner des figures géométriques : carrés et triangles, creux ou non.
Fonctions/procédures, modules, objets
Exercice 1 : procédures et fonctions
- Reprendre les instructions produisant des comptages et des figures et les placer dans des procédures avec paramètres.
- Dans une procédure affichant une figure, rendre le paramètre « symbole » optionnel avec une valeur par défaut. Tester avec un appel ne précisant pas le paramètre optionnel.
- Réaliser un appel à la procédure en utilisant les noms des paramètres et en changeant l'ordre naturel des paramètres.
- Implémenter des fonctions Python qui renvoient des figures sous forme de chaînes de caractères, sans affichage.
- Documenter au moins l'une de ces fonctions à l'aide d'une docstring (voir le cours si nécessaire). Vérifier avec help() l'affichage de cette documentation.
Exercice 2 : modules Python
- Écrire un module personnel en y plaçant au moins l'une des fonctions ou procédures écrites précédemment. Dans un autre script Python, importer ce module et appeler les procédures rendues ainsi disponibles.
- En utilisant la fonction getsizeof() du module sys, observer les tailles en octets des objets déjà créés : entier, réel, caractère, chaîne de caractères, intervalle, tuple, etc.
- Compléter avec des tests la documentation des fonctions précédentes. À l'aide du module doctest, lancer ces tests.
Fichiers en Python
Exercice 1 : lecture et écriture de fichiers
- Choisir un fichier texte contenant par exemple une œuvre littéraire (à défaut, considérer le fichier horla.txt fourni), dans lequel les paragraphes sont matérialisés par des lignes blanches.
- En Python, ouvrir le fichier et le parcourir ligne par ligne, afficher chaque ligne.
- Remplacer les lignes blanches du fichier d'origine par des balises html <BR>.
- Depuis la console Linux, rediriger les lignes produites par le script Python vers un fichier html.
- Supprimer cette redirection et programmer en Python la création du fichier html.
- Travailler (dans le script Python) le document html produit : squelette html5, association à une CSS, utilisation de balises P en lieu et place de BR, repérage d'entités, etc.
Les structures de données en Python
Chaînes de caractères en Python
(voir détails sur les listes dans le cours Python)
Exercice 1 : prise en main des chaînes de caractères
Nous considérons le texte suivant :
Bonjour {prénom} ça va aujourd\'hui ?
- Définir une variable prénom.
- Définir neuf variables contenant le texte ci-dessus,
- en l'encadrant entre apostrophes, entre guillemets ou entre triple guillemets (dans ce dernier cas, on passera une ligne dans le texte d'origine),
- en utilisant les différentes chaînes de caractères Python (standard, brute ou formatée).
- Observer le contenu de ces variables dans la console Python.
- Observer l'affichage produit par l'instruction print pour chacune de ces variables.
Exercice 2 : premières manipulations de chaînes de caractères
Placer dans une variable Python le texte suivant : « Bqrmajv,ok j!w nVqojuéso ,asv egzt ddrédclo daéf ulie, rmdewsmshajgrel.f éPùahsesxedzm yàl vlwaa vqlu e,sdtiinoànz ossuqiévka nfteeé.o ».
Longueur d'une chaîne et accès aux caractères :
- Afficher la longueur de cette chaîne.
- Afficher le 13e caractère.
Extraction de sous-chaînes :
- Extraire un caractère sur deux et placer le résultat dans une nouvelle variable.
Les questions suivantes, jusqu'à la fin de l'exercice, opèrent sur cette dernière variable.
- Extraire les sept premiers caractères.
- Extraire les neuf derniers caractères.
- Extraire sept caractères à partir du 29e.
Test d'appartenance et parcours de chaînes :
- Afficher un message indiquant si la chaîne contient ou non le mot « question ». Idem ensuite avec le mot « Question ».
- Parcourir la chaîne de caractères avec une boucle et afficher chaque caractère sur une ligne différente.
- Parcourir la chaîne de caractères pour compter et afficher le nombre d'occurrences de la lettre « e ».
Méthodes des chaînes de caractères :
- Observer les affichages produits après application des méthodes upper, lower, title, et capitalize.
- Remplacer le caractère espace par le caractère 😀.
- Trouver la position de la première occurrence de la lettre « e ». Idem pour la lettre « b ».
(pour aller plus loin sur les chaînes de caractères et les textes, voir la section « applications aux humanités »)
Structure de données Python : les listes
(voir détails sur les listes dans le cours Python)
Exercice 1 : modifications et parcours de listes
Créations de listes et placement dans des variables :
- Créer une liste vide, puis une liste contenant des éléments.
- Créer des listes à partir d'objets existants : depuis un intervalle, depuis une chaîne de caractères, depuis une autre liste.
- Construite une liste de mots à partir d'une phrase placée dans une chaîne de caractères. Reconstituer une chaîne de caractères à partir de la liste, sans séparateur entre les mots cette fois.
Choisir l'une des listes précédemment créées pour la suite de l'exercice.
- Afficher la liste et sa longueur.
- Remplacer l'une des valeurs par une nouvelle valeur.
- Supprimer la deuxième case.
- Supprimer une autre case en ciblant la valeur contenue dans la case.
- Ajouter deux nouvelles valeurs : l'une en fin de liste, l'autre en troisième position.
- Afficher à nouveau la liste et sa longueur.
- Utiliser une boucle pour parcourir les éléments de la liste et les afficher un par un. Passer en revue les différentes syntaxes possibles pour cette boucle.
Exercice 2 : tableaux de nombres
Cet exercice a pour but de traduire en Python les méthodes vues en cours d'algorithmique. Il ne s'agit donc pas, à ce stade, d'utiliser un quelconque module ou fonction existant déjà en Python.
- Définir en Python un tableau d'entiers.
Écrire (et valider sur le tableau déjà défini) les fonctions ou procédures qui :
- calcule la moyenne des nombres contenus dans un tableau donné,
- compte le nombre d'occurrences d'un élément,
- compte combien d'éléments sont supérieurs ou égaux à 10,
- recherche la valeur maximale du tableau,
- teste si un élément est présent ou non (envisager et comparer différents algorithmes).
Structure de données Python : les ensembles
Exercice 1 : extraction des entreprises depuis le corpus des curriculum vitæ
Il s'agit d'établir une liste d'entreprises, par ordre alphabétique et sans redondance, à partir d'un corpus décrivant les expériences professionnelles de diplômés de l'université de Lille. On souhaite pour cela utiliser un ensemble Python.
- Observer le fichier texte et repérer l'emplacement des entreprises.
- Débuter un script Python qui parcourt le fichier-corpus ligne par ligne.
- Sélectionner les lignes qui contiennent un nom d'entreprise.
- Découper chacune de ces lignes et en extraire le nom de l'entreprise.
- Après normalisation, ajouter le nom de l'entreprise à un ensemble Python.
- Finalement, ressortir les noms d'entreprises de l'ensemble et les afficher par ordre alphabétique.
Structure de données Python : les dictionnaires
Exercice 1 : implémentation d'un type « Enregistrement »
- Coder en Python, à l'aide de dictionnaires, le type « Étudiant » (composé d'un nom, d'un prénom, d'une année de naissance, d'une note en informatique et d'une note en littérature).
- Travailler la procédure dont le rôle est d'afficher un étudiant.
- Créer une promotion comme une liste Python d'étudiants.
- Implémenter la fonction moyenne d'un étudiant dédiée à cette représentation.
- Programmer une fonction qui, pour une discipline donnée, calcule la moyenne de la promotion dans cette discipline.
Exercice 2 : comptage des entreprises depuis le corpus des curriculum vitæ
On poursuit l'exercice sur l'extraction des noms d'entreprises. Au delà de la liste des entreprises, nous souhaitons avoir maintenant le nombre d'occurrences de chacune et un classement des entreprises, de la plus fréquente à la moins fréquente. Nous allons cette fois utiliser un dictionnaire Python pour associer une entreprise à son nombre d'occurrences.
- Reprendre le script précédent et remplacer l'initialisation de l'ensemble par l'initialisation d'un dictionnaire vide.
- À chaque rencontre avec une entreprise, incrémenter son compteur dans le dictionnaire.
- Retravailler l'affichage par ordre alphabétique des entreprises pour ajouter le compteur de chacune.
- Modifier la méthode de tri pour constituer le classement des entreprises par nombre d'occurrences.
Tableaux de tableaux
Exercice 1 : retour sur les étudiants
Nous complétons le codage réalisé dans l'exercice étudiant : il s'agit de généraliser les deux notes d'un étudiant à une liste de notes.
- Supprimer du type « Étudiant » les deux notes et lui ajouter un dictionnaire Python associant noms de disciplines et notes (une note par discipline).
- Adapter en conséquence la procédure d'affichage d'un étudiant.
- Reprendre le calcul de la moyenne d'un étudiant.
- Enfin, revoir le calcul des moyennes de la promotion par discipline.
- Généraliser encore en autorisant plusieurs notes par discipline : une promotion serait alors une liste d'étudiants-dictionnaires, contenant chacun un dictionnaire de listes de notes !
Exercice 2 : Scrabble
L'objectif est de construire une structure de données permettant d'obtenir rapidement les mots possibles à partir d'un tirage de lettres.
- Lire le fichier-dictionnaire mot par mot.
- Pour chaque mot construire sa clef :
- normaliser en passant le mot en minuscules,
- normaliser en supprimant les accents,
- trier les lettres par ordre alphabétique,
- reconstituer une chaîne de caractères avec ces lettres.
- Associer clef et mot dans le dictionnaire Python.
- Tester la structure construite avec un tirage comme adeinorrtu (lettres du mot ordinateur), que se passe-t-il ?
- Enrichir le code Python pour que chaque clef soit associée, non plus à un mot, mais à une liste de mots.
Les modules Python
Expressions régulières : le module re
Exercice 1 : recherche de mots particuliers
Pour chaque motif ci-dessous, implémenter en Python le parcours du fichier-dictionnaire et afficher les mots qui respectent la contrainte.
- Débute par une voyelle.
- N'est composé que de voyelles.
- Ne contient aucune voyelle (ni en majuscule, ni en minuscule).
- Comporte au moins deux x.
- Comporte exactement deux x.
- Comporte trois y.
- Comporte quatre z.
- Contient au moins un caractère qui n'est pas une lettre.
- N'est composé que de lettres majuscules.
- Est un palindrome.
Manipulation des documents semi-structurés : le module xml
(voir détails sur le module XML dans le cours Python)
Exercice générique
- Écrire un parser SAX qui affiche tous les événements déclenchés (début et fin de document, début et fin d'élément, feuilles textes).
- Écrire un parser SAX qui compte le nombre de balises ouvrantes dans le document XML.
- Écrire un parser SAX qui compte le nombre d'occurrences de chaque balise.
- Écrire un parser SAX qui regroupe les feuilles textes non séparées par des balises.
Squelette XML indenté
Fournir un programme Python basé sur SAX qui présente les balises d'un fichier XML quelconque de manière arborescente, c'est-à-dire :
- un nom d'élément par ligne ;
- une indentation proportionnelle à la profondeur du noeud dans l'arbre.
Le championnat : calcul de statistiques et production XHTML
Écrire un programme Python qui utilise SAX pour lire un fichier de type Foot. Celui-ci devra produire les mêmes sorties que la feuille XSLT écrite précédemment et, en plus, des statistiques par équipe (nombre de matches joués, de victoires, de points, différence de buts, etc.). Étape par étape :
- sortie HTML des matches ;
- calcul et affichage de statistiques ;
- produire un sommaire de la page et le placer en fin de document ;
- faire apparaître ce sommaire en tête de page.
Acteurs
Écrire un programme Python basé sur l'API SAX qui, qui pour tout fichier XML respectant notre DTD acteurs.dtd, produit une version html présentant :
- le contenu,
- un sommaire,
- les références résolues.
TODO list
Il s'agit d'écrire un programme Python basé sur l'API SAX et produisant une sortie HTML, bien formé et contenant un maximum d'informations de la todolist (idéalement toutes !), par exemple :
- un titre dans l'en-tête et un titre dans le corps qui reprennent le nom du propriétaire de la liste ;
- l'image associée à chaque todo ;
- le titre de chaque todo à l'aide d'un élément HTML adéquat ;
- également sa date limite ;
- ensuite, les paragraphes des commentaires ;
- puis, les items rassemblés sous la forme d'une liste HTML, les items critiques étant distingués des autres ;
- les liens (qui doivent être cliquables), les dates et les mots importants contenus dans les parties textuelles.
Extraction de méta-données
Écrire un script Python utilisant l'API DOM qui, à partir d'un fichier SVG (comme tux ou argentina), fournit les informations suivante :
- le nom de l'auteur du dessin ;
- le titre du dessin ;
- la liste des mots clés qui lui est associée ;
- le nombre de rectangle utilisés (élément rect) ;
- la taille de ces rectangles (attributs height et width).
Exemple de sortie attendue :
-- le nom de l'auteur -- L'auteur est Rory McCann ! -- le titre du dessin -- Baby Tux -- les mots clefs -- baby linux bird penguin mascot tux animal computer cute -- les rectangles -- il y en a 4 : . 42.034428 x 39.407280 . 42.034428 x 39.407280 . 61.150040 x 211.13000 . 57.995739 x 207.72755
Fonctions utiles
à la suite de l'exercice précédent, il semble opportun de disposer des fonctions Python suivantes :
- getAttributeValue(n,a) : fournit la valeur de l'attribut nommé a et associé au noeud élément n ;
- getChildElementsByTagName(n,tag) : fournit la liste des éléments fils du noeud n et nommés tag ;
- getTextContent(n) : fournit le contenu textuel associé au noeud élément n ;
- resolveElementsPath(dom,path) : path étant une liste de noms d'éléments (e1,e2,...en), cette fonction fournit les noeuds vérifiant la requête XPath //e1/e2/.../n dans la représentation dom.
Programmer ces fonctions en s'appuyant sur l'API DOM de Python. Reprendre l'exercice précédent en utilisant les fonctions nouvellement créées.
Le championnat : calcul de statistiques et production XHTML
Écrire un programme Python qui utilise DOM pour lire un fichier de type Foot et produire :
- calcul de statistiques sur le championnat (nombre de journées, de matches, taux de victoires à domicile, etc.) ;
- produire une version XHTML des matches et des résultats ;
- produire pour cette page un sommaire apparaissant en tête de document.
Caractéristiques de l'arbre DOM
- Écrire un parser qui compte le nombre de balises ouvrantes dans un document XML quelconque ;
- écrire un parser qui compte le nombre d'occurrences de chaque balise ;
- proposer et tester une fonction qui renvoie la liste des noeuds feuilles d'un arbre DOM ;
- proposer et tester une fonction qui calcule la hauteur d'un arbre DOM.
Caractéristiques d'un noeud
Écrire et tester les fonctions qui réalisent les tâches suivantes :
- déterminer si un noeud est la racine de l'arbre DOM ou pas ;
- renvoyer la liste des ancêtres d'un noeud (du noeud vers la racine, puis vice-versa) ;
- renvoyer la liste des noeud frères gauches d'un noeud donné.
Parcours d'arbres
Afficher les noeuds d'un document XML suivant les différents parcours possibles d'un arbre. En particulier, vous testerez votre programme sur un document XML représentant une expression arithmétique, comme par exemple :
<expression op="+">
<value x="5" />
<expression op="*">
<value x="7" />
<value x="6" />
</expression>
</expression>
Compter des noeuds
Écrire en Python et à l'aide de DOM une fonction qui compte dans un document XML quelconque le nombre de fois où un attribut donné apparaît avec une valeur particulière. Un appel à cette fonction pourrait ressembler à :
xmlfilename = sys.argv[1] dom = parse(xmlfilename) n = CountAttributeValue(dom,'lang','fr') print n
Modifier l'arbre DOM
Reprendre le document Foot :
- le charger dans une structure DOM ;
- créer une structure DOM vide ;
- y placer toutes les informations du fichier d'origine mais organisées par équipe et non plus par journée ;
- produire un nouveau fichier XML à partir de ce DOM.
Dessins avec la tortue Python : le module turtle
Tortue
(voir détails dans le cours Python)
- Utiliser la tortue pour dessiner un carré plein, puis une ligne de carrés et enfin un carré de carrés.
Applications disciplinaires
Lettres & Linguistique
Exercice 1 : noms d'agents
Nous souhaitons, dans cet exercice, programmer le processus qui transforme un verbe en nom d'agent (par exemple chanter donne chanteur).
Application à un unique verbe :
- Définir une variable Python contenant un verbe du premier groupe.
- Extraire son radical.
- Ajouter le suffixe -eur au radical et afficher le résultat.
Généralisation à plusieurs verbes :
- Écrire une procédure qui reprend les instructions précédemment écrites.
- Tester cette procédure sur quelques verbes bien choisis.
- Placer des verbes du premier groupe dans une liste Python.
- Parcourir cette liste et appeler la procédure sur chaque verbe.
Utilisation de fichiers :
- Créer un fichier texte contenant quelques verbes, un par ligne.
- Lire ce fichier de verbes depuis le script Python.
- Appliquer la procédure à chaque verbe du fichier.
- Produire les résultats dans un fichier html.
Extension à un fichier dictionnaire :
- Lire un fichier dictionnaire contenant tous les mots de la langue française.
- Appliquer la procédure à chaque mot se terminant par -er.
- Placer le résultat dans le fichier html, si et seulement si nom obtenu est dans le dictionnaire.
Exercice 2 : conjugaison automatique
- Définir une liste de pronoms et des listes de terminaisons (pour les premier et deuxième groupes au présent de l'indicatif).
- Définir une variable contenant un verbe.
- Extraire le radical du verbe.
- Programmer une boucle qui parcourt et affiche les pronoms.
- À chaque pronom, ajouter le radical du verbe.
- Compléter chaque ligne produite par la terminaison adéquate.
- Généraliser en procédure, stocker des verbes dans une liste, parcourir la liste et appeler la procédure sur chaque verbe.
- Lire les verbes depuis un fichier textuel.
- Produire un document html/css présentant les verbes conjugués.
- Adapter la méthode aux cas particuliers : aimer, manger, commencer, devancer, etc.
Exercice 3 : édition d'un catalogue de jouets
Un catalogue de Noël nous est fourni sous forme d'un fichier CSV et d'un dossier contenant des photos des jouets.
- Programmer en Python le parcours du fichier.
- Sur chaque ligne, récupérer le code du jouet, son intitulé et sa description.
- Mettre en page ces informations dans un document html/css produit automatiquement.
- Faire apparaître l'image associée à chaque jouet, si elle est disponible (voir la section du cours sur le module os de Python pour tester l'existence d'un fichier).
- Répérer et distinguer négativement les jouets utilisant des piles.
- Mettre en avant l'âge éventuellement associé à chaque jouet.
Envisager des variations sur le script écrit pour produire, non plus de l'html, mais d'autres formats textuels : Markdown, LaTeX, XML/TEI, etc. Utiliser ensuite les outils adéquats pour créer des documents pdf, epub, etc.
Exercice 4 : enrichissement d'un fichier XML-TEI
Nous travaillons sur le fichier fourni alice-tei.xml qu'il s'agit d'enrichir, tout en respectant le format TEI.
- Écrire un programme Python qui lit le fichier XML-TEI ligne par ligne.
- Étiqueter chaque occurrence du prénom « Alice » avec l'élément TEI « persName ».
- Enregistrer les lignes enrichies dans un nouveau fichier XML.
- Généraliser ce traitement aux autres personnages du roman et ajouter un identifiant automatique à chacun.
- Repérer également, à l'aide de l'élément TEI « w » et de son attribut « lemma », les différentes formes des verbes suivants : to look, to talk, to hear, to remember, to explain, to ask.
Exercice 5 : vérification orthographique d'un texte
Il s'agit de vérifier les mots utilisés dans un corpus, vis-à-vis de la liste des mots français.
- Lire le fichier-dictionnaire et placer les mots dans un ensemble Python.
- Parcourir le corpus ligne par ligne.
- Découper les lignes en mots.
- Tester chaque mot vis-à-vis du dictionnaire français : si un mot est absent, le signaler avec son numéro de ligne dans le corpus.
- Placer les mots inconnus dans un ensemble Python et en produire la liste par ordre alphabétique.
Exercice 6 : vocabulaire d'une œuvre
On veut cette fois identifier les mots utilisés dans un corpus, en particulier les mots les plus fréquents.
- Parcourir le corpus ligne par ligne.
- Découper les lignes en mots.
- Normaliser chacun de ces mots.
- Compter les occurrences de chaque mot.
- Produire le vocabulaire utilisé dans l'œuvre, les mots devant être classés par nombre d'occurrences.
- Utiliser la stop-list fournie pour exclure les mots d'utilisation courante.
- Corriger le code Python pour sauvegarder des expressions qui auraient été indûment coupées.
- Envisager une version html/css du vocabulaire produit, ainsi qu'une visualisation en nuage de mots.
Exercice 7 : concordancier sur un corpus littéraire
Pour cet exercice, nous travaillons sur un corpus constitué de plusieurs fichiers, fichiers numérotés ou pas. On y cherche une cible prenant la forme d'une expression régulière.
Premières recherches
Avec cette première étape, nous souhaitons prendre en charge l'expression régulière cible et obtenir un affichage équivalent à celui du grep de Linux.
- Parcourir le corpus à l'aide de Python, fichier par fichier, ligne par ligne.
- Dans chaque ligne, tester si la cible est présente.
- Si présente, afficher la ligne avec la cible mise en avant.
- Pour chaque ligne affichée, préciser son fichier d'origine et son numéro.
Premiers concordanciers
Nous cherchons maintenant à avoir un alignement des motifs repérés précédemment, en limitant la taille des contextes gauche et droit.
- Sur chaque ligne contenant la cible, récupérer le contexte gauche, la cible elle-même et le contexte droit.
- Limiter le contexte gauche aux 30 derniers caractères, le contexte droit aux 30 premiers.
- Afficher, avec des chaînes formatées et des alignements, le contexte gauche, la cible et le contexte droit.
- Ajouter des couleurs à cette sortie dans le terminal (voir les notes de cours sur le module Python termcolor).
- Réaliser une sortie html, les alignements et les couleurs étant confiés à CSS.
Trouver toutes les occurrences sur une ligne
À ce stade, nous avons trouvé une occurrence de la cible par ligne alors qu'il peut y en avoir plusieurs sur une même ligne (dans un tel cas, il est intéressant d'observer quelle occurrence a été trouvée). Nous voulons maintenant trouver toutes les occurrences présentes dans une ligne.
- Modifier l'expression régulière pour qu'elle trouve la première occurrence de la cible dans la ligne.
- Transformer le test sur la cible en une boucle et mettre à jour à chaque passage les parties gauche et droite de chaque cible trouvée.
Travail sur le texte complet
- Reprendre le parcours du corpus pour cette fois stocker toutes les lignes dans une unique chaîne de caractères.
- Adapter la boucle sur les occurrences dans une ligne pour qu'elle fonctionne sur le texte complet.
Travail sur les phrases
- Le texte étant stocké dans une unique variable, le découper en phrases.
- Adapter le travail précédent à une recherche phrase par phrase.
Contextes coupés selon les mots
- Reprendre le découpage des contextes et cette fois les couper selon les mots.
- Limiter les contextes gauche et droit à 5 mots.
- Finalement, revenir à une limite des contextes à 30 caractères mais en préservant les mots.
Dernières améliorations
- Revenir sur ce que l'on a perdu : numéros des lignes ? noms des fichiers ? symboles de ponctuation (dans et en fin de phrases) ? sortie html/css ?
- Imaginer et implémenter d'autres fonctionnalités : un regroupement des résultats par formes découvertes, un double concordancier pour chercher et visualiser des cooccurrences, etc.
Exercice 8 : anagrammes
Nous cherchons des anagrammes dans les fichiers déjà utilisés.
Dans le fichier-dictionnaire
- Trouver les mots avec le plus d'anagrammes.
- Identifier les mots d'au moins 20 caractères qui ont un anagramme.
Dans un corpus littéraire
- Dans chaque phrase, chercher les mots d'au moins quatre lettres qui ont un anagramme dans la même phrase.
Exercice 9 : cooccurrences
- Découper le corpus en phrases.
- Compter les cooccurrences de mots dans chaque phrase et consigner les compteurs dans la structure de données adéquate.
- Se restreindre aux mots pertinents, en particulier en utilisant une stop-list.
- Pour ces couples de mots et leurs compteurs, imaginer une sortie couleurs dans le terminal et une sortie html/CSS.
- Produire finalement un fichier CSV et voir les outils permettant de visualiser une matrice de cooccurrences comme un graphe.
Exercice 10 : modules
Procédures et fonctions dans un module personnel
Ajouter les procédures ou fonctions suivantes à notre module, et réécrire quelques exercices bien choisis en utilisant ce module.
- Production de l'entête et du pied d'une page html
- paramétré par : le nom du fichier à produire et le titre du document,
- utile pour : les noms d'agents, les conjugaisons, le catalogue de jouets, le concordancier.
- Lecture d'un fichier de mots
- paramétré par : chemin vers fichier,
- utile pour : expressions régulières sur dictionnaire et jeux Motus, vérification orthographique, scrabble et anagrammes.
- Lecture d'un corpus en fichiers en une unique chaîne de caractères
- paramétré par : nom du dossier contenant les fichiers,
- utile pour : concordanciers, comptage vocabulaire et cooccurrences, etc.
- Découpage d'une chaîne en mots ou phrases
- paramétré par : une chaîne de caractères,
- utile pour : concordanciers, cooccurrences, anagrammes.
- Normalisation d'un mot (minuscules et accents) et transformation en clef
- paramétré par : un mot,
- utile pour : comptages, anagrammes et scrabble.
- Concordancier
- paramétré par : chaîne de caractères, dossier, cible,
- utile pour : les différentes versions de concordanciers.
Utilisation de modules Python
Tester chaque module suivant et mettre en œuvre la fonctionnalité proposée.
- os : lancer un concordancier sur un corpus de fichiers non numérotés
- nltk : reprendre un corpus utilisé et produire un concordancier sur un mot donné.
- wordcloud : produire un nuage de mots à partir d'un vocabulaire découvert dans un corpus.
- folium : produire une carte montrant les lieux codés dans le fichier CSV fourni.
Sociologie quantitative
Exercice 1 : tableaux d'enregistrements, les restaurants
Préliminaires
-
Récupérer le dossier tp-restos.
Une liste de restaurants vous est fournie et, pour chaque restaurant, vous pouvez accéder à son nom, son adresse (à travers num et rue), sa localisation exprimée cette fois en latitude et longitude (lat et lon), sa position dans le classement (pos), sa note et le nombre d'avis qui ont été émis sur ce restaurant (votes).
Ci-dessous les premières lignes du fichier exercices.py qui montrent la récupération des restaurants, l'accès au classement et au nom d'un restaurant, et enfin une boucle sur la liste des restaurants.
from restos import liste_restos # affichage des informations sur un restaurant # à compléter def affiche_resto (resto): print('[',resto.get('pos'),']',end=' ') print(resto.get('nom')) print() # boucle sur tous les restaurants, pour affichage for resto in liste_restos: affiche_resto(resto)
- Compléter l'affichage d'un restaurant. Appliquer à tous les restaurants de la liste.
Notes et avis
- Afficher le nombre de restaurants disponibles.
- Calculer combien d'avis ont été donnés au total. Combien d'avis a reçus un restaurant en moyenne ?
- Afficher la moyenne des notes, ainsi que l'écart-type.
- Afficher le nombre de restaurants ayant une note de 4,5 ou plus.
Localisation/identification des restaurants
- Calculer la moyenne des latitudes et des longitudes. À quel endroit correspondent ces
coordonnées (utiliser par exemple ce site
ou directement Google Maps
pour visualiser sur une carte la localisation calculée) ?
Idem avec uniquement les restaurants ayant reçu plus de 50 avis. - Indiquer si oui ou non il y a un restaurant dans la rue alphonse mercier. Idem avec la rue du port.
- Afficher la description du restaurant classé à la première position. Idem avec le restaurant placé à la dernière position.
- Afficher toutes les informations disponibles sur le restaurant la ducasse. Idem pour le restaurant qui se trouve au 14 rue des postes.
- Produire la liste des restaurants se trouvant rue du molinel.
- Identifier le restaurant ayant reçu le plus d'avis.
Coup d'œil en arrière
La liste_restos jusque là utilisée correspond à la dernière année disponible. Le code Python ci-dessous vous permet d'accéder aux informations sur les restaurants pour les années précédentes.
# récupération des archives from restos import archives # constitution de la liste des restaurants 2018 liste_restos_2018 = archives["2018"]
- Reprendre les mêmes questions pour l'année précédente. Si ce n'est déjà fait, c'est le bon moment pour utiliser procédures et fonctions.
-
Quels sont les restaurants qui sont apparus lors de la dernière année ?
Des restaurants se trouvaient-ils à la même adresse ?
Quels restaurants ont disparu ? -
Identifier le restaurant qui a le plus progressé dans le classement.
Identifier le restaurant qui a chuté le plus durement. - Montrer l'évolution d'un restaurant donné au fil des années.
Adresses et rues
- Détecter les adresses partagées par plusieurs restaurants.
- Identifier la ou les rue(s) ayant le plus de restaurants.
- Trouver la meilleure rue pour les restaurants (la rue avec la meilleure moyenne de notes, ou les rues où chaque restaurant a une note strictement supérieure à 4, etc.).
- Idem avec la rue à ne pas fréquenter pour ses restaurants.
Il est possible de reprendre les deux dernières questions en jugeant une rue, non plus sur la moyenne des notes de ses restaurants, mais sur leur classement moyen.
Plus encore...
- Afficher les restaurants par ordre de classement.
- Reprendre les questions impliquant des calculs de moyennes et calculer cette fois des médianes.
- Produire une cartographie des restaurants lillois. Par exemple, une telle cartographie des restaurants est jugée satisfaisante.

Programmation Python avancée
Implémentation d'algorithmes avancés en Python
Exercice 1 : mesure de temps de calcul
Suite de l'exercice sur les tableaux de nombres. Nous nous intéressons maintenant à des tableaux beaucoup plus grands. Tout d'abord nous voulons créer de tels tableaux remplis de manière aléatoire, à l'aide du module random
Écrire les fonctions qui, pour une taille donnée n :
- fournit un tableau de n entiers aléatoires,
- construit le tableau des n premiers entiers mélangés aléatoirement.
Enfin, nous utilisons le module time (voir détails dans le cours Python) pour mesurer le temps nécessaire à l'exécution d'un bloc d'instructions.
- Sur des grands tableaux, mesurer le temps nécessaire à chacune des fonctions calculant la moyenne et recherchant un élément.
Exercice 2 : algorithmes avancés sur les tableaux
Sur les tableaux quelconques
- Implémenter une fonction index_minimum(t,d,f) qui renvoie le numéro de la case contenant la plus petite valeur du tableau t entre les cases d et f.
- Programmer un tri à bulles.
Sur les tableaux déjà triés
On suppose disposer d'un tableau de nombres rangés par ordre croissant.
- Implémenter une fonction de recherche d'un élément utilisant une boucle tant que et tirant parti du fait que les éléments sont ordonnés.
- Écrire une fonction de recherche dichotomique.
- Proposer une procédure insertion(e,t,n) qui ajoute un élément e à sa place dans un tableau t de taille n.
Autres méthodes de tri
- tri_extraction utilisant index_minimum(t,d,f) : on récupère le minimum du tableau et on le place dans la première case, on récupère le minimum du tableau privé de la première case et on le place dans la deuxième, etc.
- tri_insertion utilisant insertion(e,t,n) : prendre le ième élément et le mettre à sa place dans les i-1 premières cases déjà triées.
Exercice 3 : Comparaison expérimentale des méthodes de tri
Préliminaires
On veut dans cette séance comparer les méthodes de tri (comme le tri à bulles par exemple) en terme de temps de calcul et en fonction de la taille et de la nature des tableaux à trier.
De nouveaux points techniques sont nécessaires, essentiellement : savoir produire des fichiers texte en Python (voir détails dans le cours Python) et connaître les bases de gnuplot.
gnuplot est un outil qui permet de tracer des courbes à partir de données brutes. Par exemple, l'instruction :
$ gnuplot gnuplot> plot 'stats.dat' with lines
permet de tracer les points qui se trouvent dans le fichier stats.dat sous la forme suivante (un point par ligne, valeur en abscisse, une tabulation, valeur en ordonnée) :
100 2 200 14 300 26 400 48 500 72 600 111 700 142 800 194 900 238 1000 298
C'est ce type de fichier que l'on veut faire produire par Python (la première colonne pourrait correspondre aux tailles des tableaux considérés, la seconde aux temps de traitement nécessaires).
Fonctions à implémenter
- Écrire une fonction copie (t) qui renvoie un nouveau tableau contenant dans le même ordre les mêmes valeurs que le tableau t ; vérifier qu'une modification de la copie n'altère pas le tableau original.
- Proposer une fonction inverse (t) qui fournit un nouveau tableau contenant les mêmes valeurs que le tableau t mais dans l'ordre inverse.
-
Implémenter des fonctions pour produire des tableaux :
- une fonction tableau_premiers_entiers (n) qui produit un tableau contenant dans l'ordre tous les entiers de 1 à n,
- une fonction tableau_premiers_entiers_melanges (n) qui propose ces mêmes entiers mélangés aléaoirement,
- une fonction tableau_premiers_entiers_inverses (n) qui propose ces mêmes entiers du plus grand au plus petit.
- Proposer une procédure ligne_dans_fichier (f,n,t) dont le rôle est d'écrire dans le fichier f la valeur (numérique) de n, une tabulation, la valeur (numérique) de t et enfin un passage à la ligne.
- Écrire une fonction temps_tri_bulles (t) qui fait une copie du tableau t et renvoie le temps nécessaire au tri à bulles pour classer cette copie.
- Coder la procédure stats_melange (nmin,nmax,pas,fois) qui pour chaque taille de tableau comprise entre nmin et nmax en avançant de pas en pas produit fois tableaux mélangés aléatoirement et écrit dans un fichier le temps moyen nécessaire au tri à bulles pour classer ces tableaux.
- Même question avec la fonction stats_ordonne (nmin,nmax,pas,fois) pour des tableaux déjà ordonnés.
- Même question avec la fonction stats_inverse (nmin,nmax,pas,fois) pour des tableaux déjà ordonnés mais en ordre inverse.
- Produire à l'aide de votre code des fichiers de statistiques pour des tailles de tableau variant de 100 en 100, entre 100 et 1000, avec 5 répétitions pour chaque taille de tableau. Visualiser ces données avec gnuplot et comparer l'évolution du temps nécessaire au tri bulles selon le type de tableaux et selon leurs tailles.
- Généraliser votre code pour pouvoir également comparer les méthodes de tri entre elles : tri à bulles, tri insertion, tri extraction et tri rapide.
- Tester des modifications des méthodes de tri, calculer les écarts-types des temps de calcul sur les tableaux mélangés, explorer les possibilités de gnuplot, expliquer théoriquement les courbes obtenues.
Au final, on doit obtenir des images comme celles-ci :
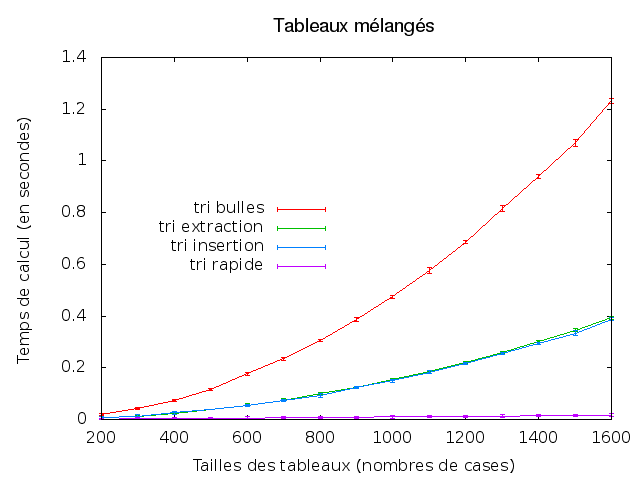
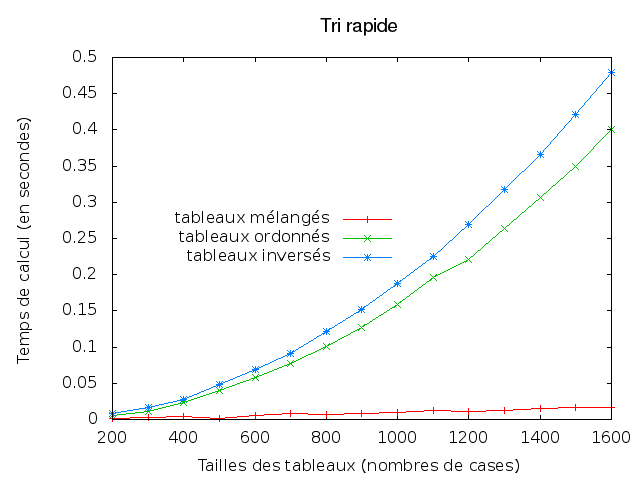
Exercice 4 : Conjecture de Syracuse
Explications
Ce problème est apparu pour la première fois dans les années 30. Puis, à nouveau, à l'université de Syracuse (New York) dans les années 50. Aucune solution n'étant trouvée, le problème s'est propagé aux autres universités américaines. Dans le contexte de la guerre froide, on évoque (comme une plaisanterie ?) une manœuvre russe pour paralyser la recherche américaine.
L'énoncé de ce problème est le suivant. On part d'un entier n auquel on fait subir une transformation :
- si n est pair, on le divise par deux ;
- si n est impair, on le multiplie par 3, et ajoute 1.
Puis, on recommence sur le résultat. Par exemple, en partant de n=10, on obtient :
Conjecture : quel que soit l'entier n, on finit par retomber sur 1.
Implémentations Python
-
Définir la carte d'identité d'un entier comme l'enregistrement de :
- cet entier,
- sa trajectoire (les entiers rencontrés jusqu'à 1),
- sa durée de vol (le nombre d'entiers rencontrés avant de trouver 1),
- son altitude maximale (le plus grand entier rencontré).
- Proposer une procédure qui affiche une telle carte.
- Écrire une fonction qui permet de tester la conjecture pour un entier donné et qui renvoie sa carte d'identité renseignée.
- Écrire ensuite une fonction qui teste tous les entiers dans un intervalle donné et renvoie toutes les cartes d'identité de ces entiers.
- Utiliser cette fonction pour afficher les cartes présentant une durée de vol strictement supérieure à 100.
- Implémenter un tri à bulles pour classer des cartes par altitude décroissante.
Exercice 5 : Chiffrement et décryptage
Préliminaires
Dans cette séance, on s'intéresse au chiffrement de textes par substitution, à leur déchiffrement, et enfin au moyen de casser un tel cryptage. Un chiffrement par substitution consiste simplement à remplacer systématiquement une lettre par une autre.
Certains chiffrements par substitution sont dits par décalage ou appelés chiffre de César : dans ces cas, une lettre et sa remplaçante sont toujours séparées dans l'alphabet par le même nombre de lettres. Un chiffrement par décalage répandu sur le web se nomme ROT13 : une lettre et sa remplaçante sont à une distance de 13 dans l'alphabet (le a est remplacé par le n, le b par le o, etc.).
Par souci de simplicité, on ne considère que des textes en minuscules, sans accent et sans symbole de ponctuation. Seul l'espace est utilisé entre les mots mais n'est pas remplacé par le chiffrement.
Cette séance va nécessiter de traiter des chaînes de caractères qu'il peut être commode de voir comme des listes de caractères, ce que permet Python.
Concernant les caractères eux-mêmes, on rappelle qu'il est possible de repérer un caractère par un numéro (son code ASCII).
Nous aurons également besoin de stocker les correspondances entre lettres, ce qui peut être fait à l'aide de dictionnaires Python (que nous avions déjà utilisés pour coder des enregistrements).
Enfin, pour décrypter un texte sans connaître la règle de chiffrement, il est courant d'utiliser la fréquence d'apparition des lettres dans la langue choisie. On considérera qu'en français les lettres se rangent comme suit, de la plus fréquente à la moins fréquente :
e a i t s n l u r o d m c p v q h f b g j x y w z k
Fonctions à implémenter
On va d'abord réaliser et tester quelques fonctions pour gérer les dictionnaires, chiffrer et déchiffrer des textes.
- chiffrement_lettre (l,d) renvoie la correspondance de la lettre l dans le dictionnaire d si cette correspondance existe, renvoie la lettre l elle-même sinon.
- chiffrement_phrase (p,d) construit une nouvelle chaîne de caractères correspondant au chiffrement caractère par caractère de la phrase p à l'aide du dictionnaire d. Définir un dictionnaire et tester ces fonctions en codant une phrase quelconque.
- inverse_dico (d) renvoie un nouveau dictionnaire qui inverse les clefs et les valeurs du dictionnaire d. Tester en déchiffrant la phrase précédemment codée.
- dico_rot_13 () construit un dictionnaire correspondant au chiffrement en ROT13. Tester à nouveau pour chiffrer une phrase quelconque. Quelles solutions sont possibles pour le déchiffrement ?
On veut maintenant déchiffer un texte codé par une technique de substitution mais on ne dispose pas du dictionnaire utilisé. L'objectif est de décoder le texte mystère suivant.
Texte à décoder
Les étapes à réaliser sont les suivantes.
- compte_lettres (p) construit un dictionnaire faisant correspondre chaque lettre apparaissant dans la phrase p à son nombre d'occurrences dans cette même phrase. Tester sur le texte mystère.
- tri_bulles_dico (d) est un tri à bulles modifié pour renvoyer les clefs d'un dictionnaire d, ordonnées par valeurs décroissantes. Tester sur le dictionnaire précédemment calculé par compte_lettres.
- arrays2dict (ks,vs) renvoie un dictionnaire dont les clefs correspondent au tableau ks et qui associe pour chacune de ces clefs la valeur se trouvant à la même position dans le tableau vs. Utiliser cette fonction pour combiner le tableau fourni par tri_bulles_dico et le tableau des lettres de l'alphabet classées par fréquences décroissantes dans la langue française.
- decrypte (pc,ll) doit décrypter la phrase pc à l'aide des lettres de l'alphabet rangées par ordre de fréquence décroissante dans la langue utilisée et disponible dans le tableau ll. Décoder le texte mystère à l'aide de cette fonction.
Implémentation de types abstraits en Python
Exercice 1 : Implémentation du type abstrait « Entier »
- Implémenter le type abstrait « Entier » vu en cours en utilisant... les entiers de Python.
-
Coder les opérations addition et multiplication
sur ce nouveau type.
[ voir la correction ][ récupérer ]
-
Implémenter à nouveau le type abstrait « Entier » vu en cours
cette fois en s'appuyant sur les listes de Python
(une liste de n éléments quelconques représentera l'entier n).
[ voir la correction ][ récupérer ]
- Est-il nécessaire de recoder les opérations addition et multiplication ?
Exercice 2 : Implémentation du type abstrait « Pile »
- Implémenter le type abstrait « Pile » vu en cours.
- Écrire une fonction qui permet d'inverser une pile.
-
Écrire une fonction qui prend en entrée un texte composé
de différentes parenthèses, accolades, crochets, ouvrants ou fermants,
et qui vérifie que l'expression est bien parenthésée.
On pourra par exemple suivre les étapes suivantes :- une fonction qui prend en entrée un caractère et renvoie vrai s'il s'agit d'un symbole ouvrant et faux sinon,
- une fonction qui prend un symbole ouvrant et fournit en retour le caractère fermant correspondant,
- enfin, la fonction de vérification.
- Écrire une fonction qui évalue une
expression polonaise inversée,
composée d'entiers entre 0 et 9 et des quatre opérations élémentaires.
On pourra par exemple suivre les étapes suivantes :- une fonction qui prend en entrée un caractère et renvoie vrai s'il s'agit d'une opération élémentaire et faux sinon,
- une fonction qui prend un symbole-opération et deux entiers et qui renvoie le résultat de l'opération,
- enfin, la fonction d'évaluation.
Quelques corrections
- prise en main de Python : [ voir la correction (partielle) ][ récupérer ]
- implémentations du type abstrait « Étudiant » : [ voir la correction version 1 ][ récupérer ] [ voir la correction version 2 ][ récupérer ]
- utilisation pour gérer une promotion d'étudiants : [ voir la correction ][ récupérer ]

{kind=link}
{kind=link}