Travaux pratiques Perl
A. Prise en main de perl
[ 1 ] Affichages et premières boucles
- Écrire une boucle Perl qui affiche les entiers de 1 à 10. Utiliser d'abord une boucle while puis essayer avec une boucle for.
- Généraliser au sein d'une procédure avec un paramètre.
- Définir un tableau d'entiers, puis un tableau de mots.
- Proposer une procédure permettant d'afficher le contenu de tels tableaux.
B. Production automatique de textes
[ 2 - traitement de la langue ] Nom d'agent dérivé d'un verbe
- Définir une variable contenant le verbe chanter.
- Supprimer les deux dernières lettres de ce mot et les remplacer par les lettres eur.
- Produire une phrase intégrant ces deux mots et explicitant leur lien sémantique.
- Généraliser ce code en écrivant une procédure traitant n'importe quel verbe du premier groupe.
- Définir un tableau Perl contenant plusieurs verbes du premier groupe.
- Ajouter au programme Perl une boucle sur ce tableau et un appel à la procédure pour chacun des verbes.
[ 3 - traitement de la langue ] Construction de verbes par préfixation en dé-
- Définir une variable contenant un verbe comme chanter ou axer.
- Récupérer la première lettre du verbe.
- Tester si cette première est une voyelle ou non et lui ajouter le préfixe adéquat pour produire un nouveau verbe (déchanter ou désaxer).
- Afficher une phrase présentant le résultat.
- Concevoir sur papier l'algorithme précis qui à partir d'un verbe construit le verbe décrivant le processus inverse. Il permettra en particulier de traiter sans erreur les verbes chanter, axer, boucher, saler, équilibrer, hydrater et stabiliser.
- Écrire une fonction qui prend une lettre en entrée et qui renvoie vrai ou faux selon que la
lettre est une voyelle ou non. Cette fonction pourra :
- soit utiliser un SI ALORS SINON dont la condition est une disjonction de tests d'égalités sur les voyelles ;
- soit définir un tableau Perl contenant les voyelles et utiliser une boucle pour parcourir ce tableau à la recherche de la lettre fournie.
- Fournir une procédure qui implémente l'algorithme de préfixation en dé-.
- Définir un tableau de verbes.
- Ajouter une boucle pour tester la procédure écrite vis-à-vis de chaque verbe du tableau.
- Proposer la lecture d'un fichier de verbes et la production d'une page html.
[ 4 ] Conjugaison automatique
- Définir une variable contenant un verbe, soit du premier groupe, soit du deuxième groupe.
- Définir un tableau à six cases contenant les pronoms personnels.
- Définir un tableau contenant les marques de conjugaison au présent de l'indicatif pour les verbes du premier groupe, et un autre pour les terminaisons des verbes du deuxième groupe.
- Récupérer le radical et la terminaison du verbe. Écrire un test qui décide si le verbe appartient au premier ou au deuxième groupe.
- Produire l'affichage des formes conjuguées de ce verbe au présent de l'indicatif, chaque forme étant précédée du ou des pronom(s) personnel(s) adéquat(s).
- Définir un tableau de verbes et produire à l'aide d'une boucle les conjugaisons pour chaque verbe.
- Revenir sur le code déjà écrit et proposer des procédures pertinentes.
- Travailler la sortie (apparence utilisant HTML) et les entrées (lire ce qui peut l'être dans des fichiers).
[ 5 ] Pipotron façon radio Londres
- Définir un tableau de verbes et un tableau de groupes nominaux.
- Tirer au hasard un groupe nominal, un verbe et un cod.
- Conjuguer automatiquement le verbe en fonction du groupe nominal choisi. Utiliser pour cela le code de l'exercice précédent, placé dans une fonction.
- Combiner les trois éléments pour obtenir une phrase.
- Lire verbes et groupes nominaux dans des fichiers et produire un fichier html de cent phrases produites aléatoirement.
C. Expressions régulières et traitement de fichiers
[ 6 ] Expressions régulières et dictionnaire
Parcourir les mots du fichier-dictionnaire et, indépendamment des minuscules/majuscules ou des lettres accentuées, afficher uniquement les mots qui :
- commencent par une voyelle,
- ne sont composés que de voyelles,
- ne contiennent aucune voyelle, que ce soit en majuscule ou en minuscule,
- comportent (au moins) deux x,
- comportent (exactement) deux x,
- comportent trois y,
- comportent quatre z,
- contiennent au moins un caractère qui n'est pas une lettre,
- ne sont composés que de lettres en majuscule,
- sont des palindromes.
[ 7 ] Catalogue de jouets
- Récupérer le fichier kdos.txt et le dossier kdos-images.
- Avec Perl, parcourir le fichier et pour chaque jouet récupérer chacune des informations disponibles (numéro, intitulé et description).
- Produire ces informations dans un fichier html auquel est associé une feuille css.
- Faire apparaître l'image associée à chaque jouet.
- Répérer et distinguer les jouets utilisant des piles.
- Mettre en avant l'âge éventuellement associé à chaque jouet.
[ 8 - traitement de la langue ] Travaux sur un dictionnaire
Nous revenons sur l'exercice concernant les noms d'agent dérivés d'un verbe. Il s'agit d'obtenir tous les noms plausiblement construits par le processus discuté en cours (et seulement par lui), en écartant au mieux les erreurs.
- Reprendre la liste des verbes du premier groupe et le code produisant pour chacun le nom d'agent correspondant : vérifier que ces noms sont bien dans le dictionnaire et faire apparaître ceux qui n'y sont pas.
- Parcourir le dictionnaire à la recherche des mots se terminant par -eur.
- S'assurer pour chaque candidat que le verbe correspondant existe bien dans la langue française (ou autrement dit, qu'il est bien présent dans notre dictionnaire).
- Stocker les candidats dans un fichier texte.
Nous voulons maintenant trouver dans le dictionnaire les verbes susceptibles d'avoir été construits par une préfixation en dé- d'un verbe existant et décrivant donc un processus inverse. Il s'agit d'obtenir tous les verbes plausiblement construits par cette méthode de préfixation, tout en minimisant le nombre de mots sélectionnés qui ne sont pas de tels verbes.
- Lire le fichier-dictionnaire (un mot par ligne) et passer en revue les mots du dictionnaire.
- Retenir ceux qui d'après leurs terminaisons sont susceptibles d'être des verbes à l'infinitif.
- Ne garder que ceux présentant l'un des préfixes vus en cours.
- Vérifier que le mot privé de son préfixe est bien dans le dictionnaire.
- Enfin, stocker les candidats dans un fichier texte.
Dernière tâche sur le dictionnaire...
- Trouver les mots construits à partir d'un préfixe comme
hippo-, aéro-, rhino-, poly-, biblio-, etc.
ou d'un suffixe comme -thèque, -vore, -phage, -mètre, -culture, etc.
D. Travaux sur corpus
[ 9 ] Extraction des entreprises depuis le corpus des curriculum vitæ
- Implémenter le parcours, ligne par ligne, du fichier contenant le corpus.
- N'afficher que les lignes correspondant à des expériences professionnelles.
- Extraire de ces lignes d'expériences les noms des entreprises employeuses.
- Produire la liste des entreprises, sans redondance, par ordre alphabétique.
- Compter les nombres d'occurrences de chaque entreprise dans le corpus et faire apparaître ces compteurs dans la liste des entreprises.
- Ordonner cette liste, de l'entreprise la moins fréquente dans le corpus à la plus fréquente.
[ 10 - sociologie ] Extractions et visualisations depuis une base de prénoms
- Récupérer le fichier « France » des prénoms de l'INSEE au format .csv. Lire et comprendre la documentation.
- Compter le nombre de naissances depuis 1900.
- Donner le nombre de prénoms distincts. Idem en se restreignant aux femmes, puis aux hommes.
- Produire le classement des prénoms du moins fréquent au plus fréquent, de 1900 à aujourd'hui.
- Pour chaque année et chaque sexe, indiquer le prénom le plus fréquent.
- Trouver les prénoms les plus rares, c'est-à-dire les prénoms qui ne sont qu'avec XXXX comme année. Classer du moins fréquent au plus fréquent.
- Afficher le classement des trente prénoms les plus fréquents entre 1961 et 1970. Puis ce classement pour la période 2011-2020.
- Comparer de la même manière les trente prénoms les moins fréquents pour la période 1961-1970 et 2011-2020.
- Lister les prénoms qui étaient utilisés entre 1961-1970 mais plus du tout en 2011-2020. À l'inverse, quels prénoms étaient absents entre 1961 et 1970 mais présents entre 2011 et 2020.
- Compter le nombre de prénoms distincts par période.
- Tracer la courbe montrant l'évolution pour un prénom au fil du temps. Généraliser à plusieurs prénoms et à une période quelconque. Par exemple, pour comparer les prénoms STONE, DALIDA, RINGO, SHEILA et MIKA entre 1951 et 2020.
- Tracer les courbes des effectifs hommes/femmes en fonction de l'année (ramener chaque effectif à 10,000 naissances).
- Compter et visualiser les prénoms de trois lettres.
- Quels sont les prénoms les plus courts ? Quels sont les prénoms les plus longs ?
- Tracer le nombre de prénoms distincts en fonction de l'année.
- Tracer les courbes montrant l'évolution des longueurs des prénoms.
- Tracer la courbe de l'évolution de la position d'un prénom dans les classements annuels.
- Utiliser les expressions régulières pour comparer l'évolution des variantes orthographiques d'un prénom (par exemple, le prénom Christelle, avec ou sans h, avec un i ou un y, avec un ou deux l, avec ou sans le e final, etc.).
Des exemples de résultats attendus sont visibles sur ce fil Twitter.
[ 11 ] Vocabulaire et vérification orthographique
Préparation du corpus.
- Depuis le corpus curriculum vitæ, sélectionner uniquement les lignes de texte libre.
- Découper ces lignes en mots.
Établissement du vocabulaire.
- Compter pour chaque mot son nombre d'occurrences dans le corpus.
- Faire apparaître ce vocabulaire, du mot le moins fréquent au mot le plus fréquent.
- Utiliser la stop-list et écarter des résultats les mots vides de sens.
- Travailler la présentation du classement : page html, nuage de mots, etc.
- Voir la possibilité de cartographier le vocabulaire.
Vérification orthographique : nous souhaitons maintenant croiser le vocabulaire utilisé dans le corpus avec notre dictionnaire.
- Signaler les mots présents dans les paragraphes du corpus mais absents du dictionnaire.
- Indiquer le numéro de la ligne du corpus où le problème a été détecté.
- Produire ce compte-rendu d'erreurs probables dans un fichier texte ou html.
[ 12 - traitement de la langue ] Repérage d'entités particulières dans les textes
Depuis un corpus de votre choix, nous cherchons à extraire les noms propres, en explorant plusieurs pistes :
- afficher les mots fréquents dans le corpus avec une majuscule, mais absents du dictionnaire lorsque écrits tout en minuscules,
- découper le corpus en phrases,
- repérer les mots portant une majuscule même lorsqu'ils ne sont pas en début de phrase,
- se baser sur TreeTagger pour repérer les noms propres.
Différentes variations peuvent être envisager autour TreeTagger pour lister :
- les adjectifs présents dans le corpus,
- les adverbes utilisés,
- les temps des verbes conjugués.
Nous cherchons maintenant dans le corpus des mots dont on a préalablement établi la liste (par exemple à l'aide des premières questions de cet exercice), cette liste étant stockée dans un fichier texte :
- compter, dans le corpus, les occurrences des mots du lexique établi,
- à partir de deux listes différentes, établir deux compteurs distincts, les nombres d'occurrences des mots de chaque liste.
Enfin, nous nous intéressons au repérage des dates :
- proposer et programmer une stratégie pour trouver les indications de date dans le corpus.
[ 13 - traitement de la langue ] Concordancier
Nous travaillons sur un corpus de plusieurs textes, chaque texte est dans un fichier, tous les fichiers sont dans un même dossier. Voici le cahier des charges de notre concordancier.
- Trouver les lignes d'un fichier qui comportent le mot cherché.
- Faire apparaître ces lignes en faisant ressortir le mot cible.
- S'assurer que l'on a toutes les occurrences en particulier si elles sont sur une même ligne.
- Aligner les occurrences trouvées au centre et permettre de visualiser ainsi les contextes gauche et droit.
- Limiter le nombre de caractères dans les fenêtres gauche et droite.
- Puis compter la taille de ces fenêtres en mots, en prenant garde à ne pas perdre la ponctuation...
- La fenêtre doit aussi être limitée par la phrase dans laquelle a été trouvée le mot cherché (nous ne voulons voir apparaître ni la fin de la phrase précédente, ni le début de la phrase suivante).
- Faire apparaître le nom de fichier et le numéro de la ligne.
- Permettre de rechercher, non plus un mot précis, mais un motif, exprimé comme une expression régulière.
- Regrouper les occurrences par formes observées.
Par exemple, un tel concordancier est jugé satisfaisant.
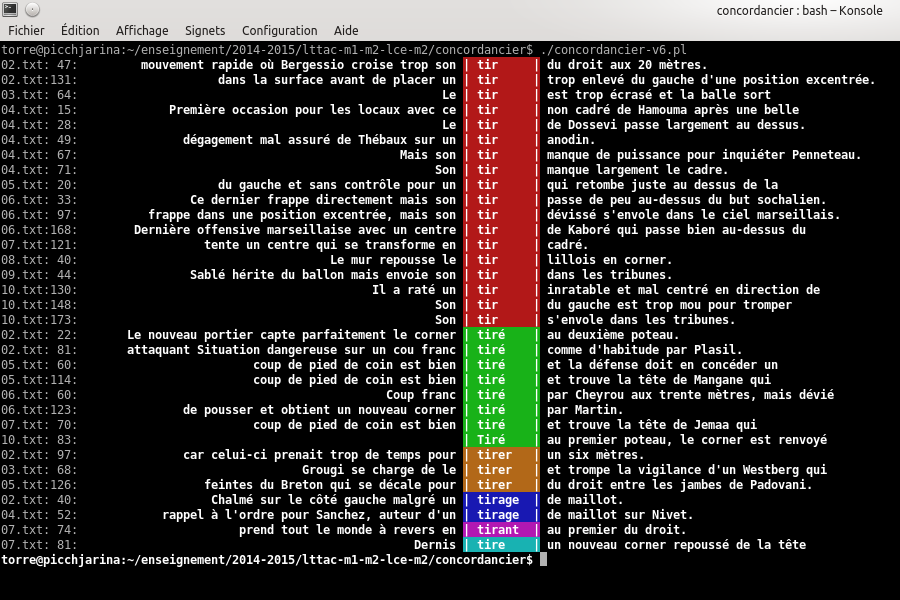
D'autres exemples de résultats possibles sont visibles sur ce fil Twitter.
E. Autres exercices
[ 14 ] Une aide pour le scrabble
Pour cet exercice, nous nous intéressons aux jeux de mots qui nécessitent de trouver des anagrammes à partir d'un tirage de lettres : Scrabble, le mot le plus long, Wordox mais aussi mots croisés ou fléchés, etc.
Préparation d'une structure de données adaptée
- Lire le fichier des mots français nous servant de dictionnaire.
Pour chaque mot,
- remplacer les lettres accentuées par leurs versions non accentuées, normaliser au besoin,
- découper le mot en lettres,
- classer les lettres par ordre alphabétique,
- construire la chaîne de caractères correspondant à ces lettres ordonnées,
- associer cette clef au mot d'origine dans un tableau associatif.
Recherche d'anagrammes
- Tester sur quelques tirages produits à la main.
- S'il n'existe pas d'anagramme utilisant toutes les lettres, considérer des mots plus petits.
- Proposer un affichage par taille des mots.
En normalisant, en particulier en enlevant les accents, mais aussi en acceptant de ne pas utiliser toutes les lettres, nous avons pu introduire des doublons dans notre structure de dictionnaire...
- Comment éviter ces doublons ?
- Comment se souvenir des versions accentuées des mots ?
Tirage et comptage des points au Scrabble
Dans cette partie, nous nous référons aux règles du Scrabble telles que présentées sur la page wikipedia dédiée à ce jeu.
- Définir un tableau associatif qui à chacune des 26 lettres non accentuées de l'alphabet associe le nombre de jetons correspondant.
- Produire un tableau classique imitant le sac de lettres : nous devons y trouver les lettres de l'alphabet et le nombre d'occurrences de chaque lettre correspond à ce qui a été défini dans le tableau associatif précédent.
- Définir un tableau associatif qui à chacune des 26 lettres non accentuées de l'alphabet associe le nombre de points correspondant.
- Proposer une fonction Perl qui à partir d'un tableau de lettres calcule le nombre de points correspondant à ces lettres.
- Proposer une fonction semblable qui cette fois travaille à partir d'un mot vue comme une chaîne de caractères Perl.
- Simuler le tirage aléatoire de sept jetons dans le sac. De préférence, on s'assurera que le tirage se fait sans remise.
- Déterminer quels mots peuvent être écrits avec ces sept lettres choisies au hasard et indiquer le nombre de points associé à chaque mot.
- Produire tous les mots possibles (en évitant si possible les doublons) à partir du tirage, classés par nombre de points.
Anagrammes avec joker
- Intégrer la possibité de tirer un ou deux jokers.
- À nouveau, soigner l'affichage.
Prise en compte du plateau de jeu
Nous souhaitons maintenant prendre en compte, en plus des lettres tirées, d'autres lettres dont on nous indique qu'elles sont disponibles sur le plateau de jeu.
- Considérer la possibilité d'avoir une lettre supplémentaire, déjà présente dans un mot du plateau de jeu.
- Généraliser à plusieurs lettres et à un motif, afin de « croiser » plusieurs mots du plateau.
- Chercher à « voler » un mot complet, en lui ajoutant un lettre au début ou à la fin. Quels mots pouvons-nous construire sur cette lettre ?
- Proposer de compléter un mot présent sur le plateau, cette fois en ajoutant au moins deux lettres.
- « Coller » un mot du plateau... trouver un mot à partir du tirage qui, une fois accolé à un mot du plateau, engendre des mots valides de deux lettres.
- Prendre en compte les cases bonus du plateau de jeu.
Reste à combiner le tout : plateau, jokers, etc.
[ 15 ] Cartographie d'un vocabulaire
- Dans chaque section du corpus, compter des cooccurences des mots de la top-list c'est-à-dire déterminer, pour chaque couple de mots, combien de fois ces deux mots apparaissent dans une même section du corpus.
- Produire un fichier texte contenant la matrice des cooccurences,
les valeurs étant séparées par des points-virgules.
On n'oubliera pas un première ligne et une première colonne contenant les mots de la top-list. - Vérifier l'ouverture du fichier produit dans un tableur.
- Finalement, il s'agit de visualiser les résultats dans le logiciel
gephi,
en suivant les indications suivantes :
- cliquer sur « nouveau projet / ouvrir un fichier de graphe », sélectionner le fichier précédemment créé et indiquer « type du graphe : non dirigé »,
- l'onglet « Laboratoire de données » permet de retrouver notre matrice de cooccurences, pour la suite nous travaillons dans l'onglet « Vue d'ensemble »,
- dans la colonne de droite, cliquer sur « Exécuter » pour calculer le « Degré pondéré » de chaque nœud,
- dans le colonne de gauche, régler les tailles des nœuds (icône
 )
entre 20 et 75, selon le degré pondéré des nœuds, appliquer,
)
entre 20 et 75, selon le degré pondéré des nœuds, appliquer,
- choisir force atlas comme méthode de spatialisation avec 100,000 comme force de répulsion et la case ajustement par taille cochée, exécuter puis arrêter,
- dans la colonne de droite, dans les paramètres « vue générale du réseau », lancer les calculs de la « modularité » avec une valeur de la résolution entre 0.5 et 1 (par exemple 0.6),
- dans la colonne de gauche,
choisir les couleurs de nœuds (icône
 )
en fonction de la modularity class, appliquer,
)
en fonction de la modularity class, appliquer,
- onglet « Prévisualisation », dans « labels de nœuds », cocher affichage des labels, décocher « taille proportionnelles » et choisir la police Arial gras 48, rafraîchir.
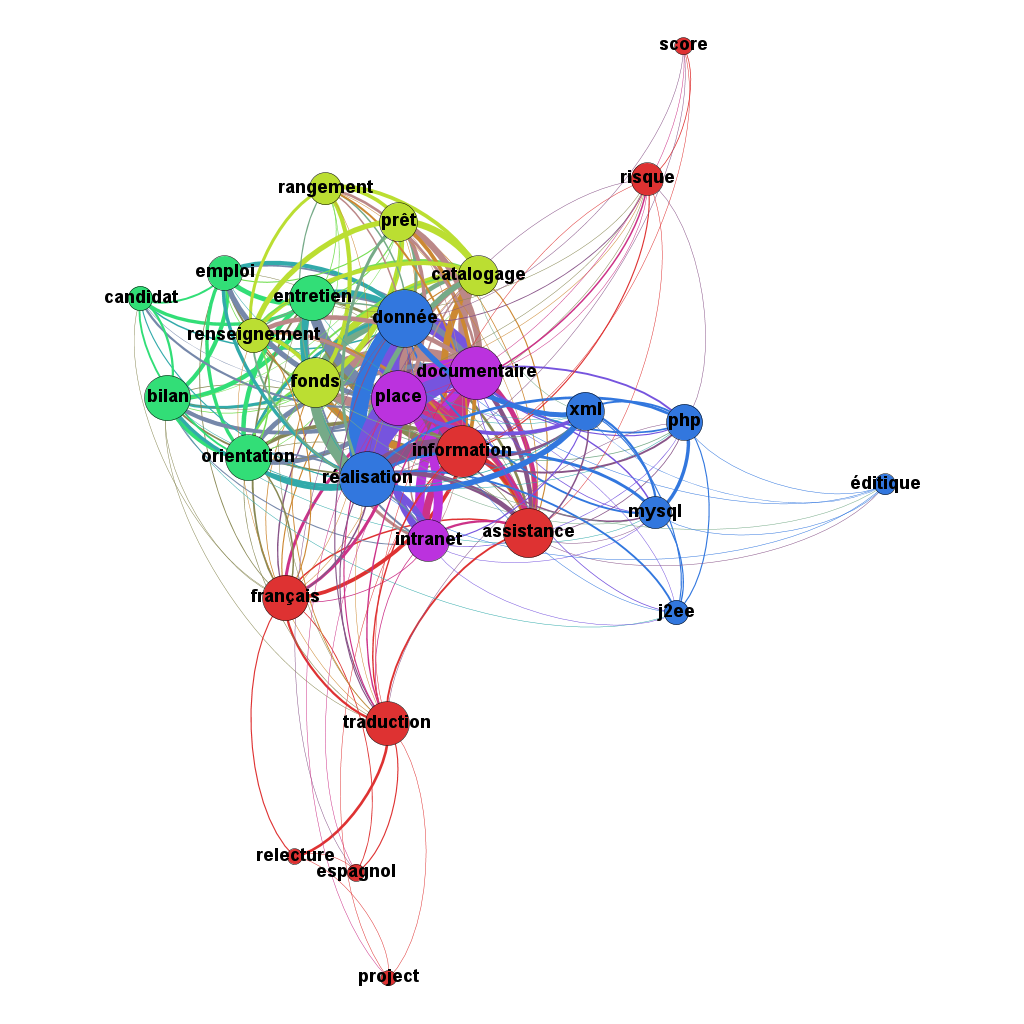
[ 16 ] Décryptage d'un texte codé
Nous nous intéressons aux méthodes de codage par substitution (une lettre est systématiquement remplacée par une autre). Avant de commencer, vous pouvez lire la page wikipedia sur ce sujet.
Dans un premier temps, nous souhaitons déchiffrer un texte codé par une technique de substitution mais sans disposer de la clef utilisée. L'objectif est de décoder le texte mystère suivant.
Texte à décoder
Pour décrypter un texte sans connaître la règle de chiffrement, il est courant d'utiliser la fréquence d'apparition des lettres dans la langue choisie. Nous considérerons qu'en français les lettres se rangent comme suit, de la plus fréquente à la moins fréquente :
e a i t s n l u r o d m c p v q h f b g j x y z w k
- Définir une variable Perl contenant le texte crypté fourni ci-dessus et une autre variable contenant le tableau des lettres de l'alphabet par ordre de fréquence dans la langue française.
- Proposer un code Perl qui construit un tableau associatif faisant correspondre chaque lettre apparaissant dans la phrase mystère à son nombre d'occurrences dans cette même phrase.
- Ordonner les clefs du tableau associatif obtenu par valeurs décroissantes, autrement dit obtenir la liste des lettres présentes dans le texte mystère classées par nombre d'occurrences décroissant.
- Construire un tableau associatif dont les clefs correspondent au tableau obtenu à la question précédente et dont les valeurs correspondent au tableau des lettres de l'alphabet classées par fréquences décroissantes dans la langue française (la correspondance se fait position par position dans les deux tableaux).
- Utiliser ce tableau pour finalement décrypter la phrase mystère.
Dans un second temps, nous pouvons généraliser le travail accompli et nous donner en Perl les moyens de coder et décoder un texte.
- Définir un tableau associatif mettant en correspondance chaque lettre de l'alphabet avec une autre lettre.
- De la même manière, définir un tableau associatif définissant le codage ROT13 dans lequel une lettre et sa remplaçante sont à une distance de 13 dans l'alphabet (le a est mis en correspondance avec le n, le b avec le o, etc.).
- Écrire la fonction chiffrement_lettre($l,%t)
qui renvoie la correspondance de la lettre $l dans le tableau associatif %t
si cette correspondance existe, et renvoie la lettre $l elle-même sinon.
Tester à l'aide des tableaux précédemment définis. - Écrire la fonction chiffrement_phrase($p,%t) qui construit une chaîne
de caractères correspondant au chiffrement caractère par caractère de
la phrase $p à l'aide du tableau associatif %t.
Tester en codant une phrase quelconque, à l'aide des tableaux précédemment définis.
Comment décoder le résultat obtenu ? - Proposer une fonction inverse_code(%t) qui renvoie un tableau associatif,
lequel reprend les clefs et les valeurs du tableau associatif %t mais en les inversant.
Tester en déchiffrant les phrases précédemment codées.
[ 17 ] Écriture intuitive avec un pavé numérique
- Définir à l'aide d'un tableau associatif Perl la correspondance entre les lettres de l'alphabet et les touches du clavier (par exemple on associera la valeur 2 à chacune des lettres a, à, â, ä, b, c et ç).
- Lire le fichier des mots français nous servant de dictionnaire et associer chaque mot et sa version numérique (par exemple 268268 => coucou).
- Proposer une interprétation de la phrase suivante, le chiffre 0 délimitant les mots :
2682680266636802208202436053702672467066032480330520 77647266284660283203370822532890277624284370876702665
