Projet Indana, GRAppA, travail d'octobre 2002
Retour au projet INDANA.
Préliminaires
Nos travaux précédents portaient sur l'identification des exemples de la zone grise à partir de l'observation d'un algorithme d'apprentissage, les exemples posant problème à notre algorithme étant considérés comme gris.
Nous avons été confortés dans cette approche par le fait que les exemples jugés difficiles par différents algorithmes (C4.5 et DiVS de Michèle) étaient souvent les mêmes.
Finalement, nous avons réalisé que nous détections la typicité de chaque exemple dans sa classe : sont défavorables les EVENT qui ne présentent pas de risque et les NO EVENT qui présentent des risques sévères. Or, ceci les médecins savent déjà le faire à travers des mesures de risque comme celle de Pocock. Et, effectivement, les exemples difficiles pour l'apprentissage peuvent être déterminés par le simple calcul du score de Pocock.
Nous avons également proposé notre propre score, établi de manière simple, et identifiant également les exemples délicats ; ce score sera désigné par Fabien (août 2002).
Dans la suite, nous allons considérer des ensembles d'exemples où les exemples gris ont été écartés selon la procédure suivante : on garde les EVENT les plus à risque et les NO EVENT les moins à risque selon Pocock, dans une proportion donnée et identique pour les deux classes. Cette proportion constitue le niveau de coupure, paramètre que nous ferons varier systématiquement.
Chaque apprentissage utilisera GloBo, lequel possède deux paramètres majeurs :
- redondance qui indique combien de règles doivent être produites à partir d'un exemple graine ;
- essais_nettoyage qui indique l'effort à accomplir pour diminuer le nombre d'attributs dans chaque règle apprise.
Les points discutés dans la suite sont les suivants :
- évaluation des théories apprises hors zone grise ;
- capacité prédictive de ces théories et évaluation de l'hypothèse de François ;
- caractérisation de la zone grise ;
- test de calibrage des scores ;
- utilisation des scores en prédiction ;
- définition d'un nouveau score à l'aide de GloBo ;
- bilan et perspectives.
Théories apprises hors zone grise
Protocole
On essaye d'apprendre des théories après avoir sélectionné les données comme indiqué ci-dessus, puis d'évaluer ces théories sur des critères de généralité et de compréhensibilité.
Ici, la redondance était réglée à 80 et les essais_nettoyage à 1000.
Résultats
| 5 % | 10 % | 15 % | 20 % | 25 % | 30 % | 35 % | 40 % | 45 % | 50 % |
| 55 % | 60 % | 65 % | 70 % | 75 % | 80 % | 85 % | 90 % | 95 % |
Par exemple, avec une coupure à 60 %, on apprend la règle suivante
Sexe vaut Male Age est entre 70.00 et 89.00 Taille est entre 157.48 et 175.26 Cholestérol total est entre 5.20 et 8.22 |
Age est entre 70.00 et 96.00 Diabète vaut YES |
Même s'il n'y a pas là de découverte scientifique, il est réconfortant de retrouver des éléments connus des médecins.
On pourrait objecter que nous réapprenons les règles de Pocock ; c'est sans doute vrai, en partie. Il reste cependant notable que cela se produit pour des points de coupure aux alentours de 60 %, et plus jamais ensuite. L'intérêt de cette région est confirmé par les mesures suivantes.
Couverture de la première règle apprise
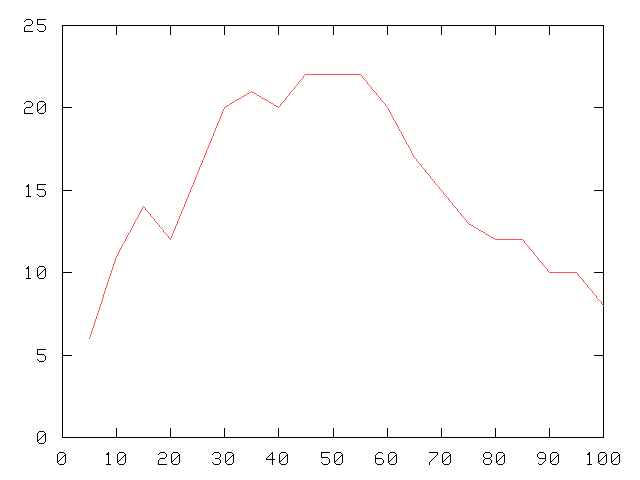
| On voit croître le nombre d'exemples couverts par la première règle de la théorie apprise jusqu'à un niveau de coupure de 45 %, puis on assiste à une stabilisation entre 45 et 55 % et enfin à une décroissance du nombre d'exemples couverts (dans cette dernière phase, il est clair que des exemples gris ont été introduits). |
Nombre de règles apprises
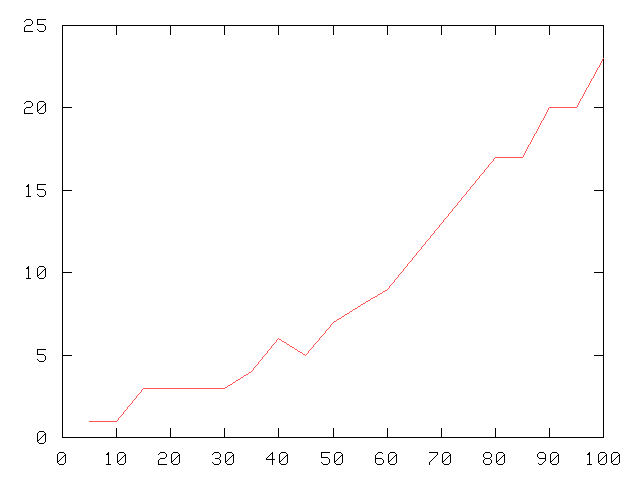
| Le nombre de règles impliquées dans la théorie apprise augmente lentement puis explose à partir d'un niveau de coupure proche de 60 %. |
Nombre moyen d'attributs par règle apprise
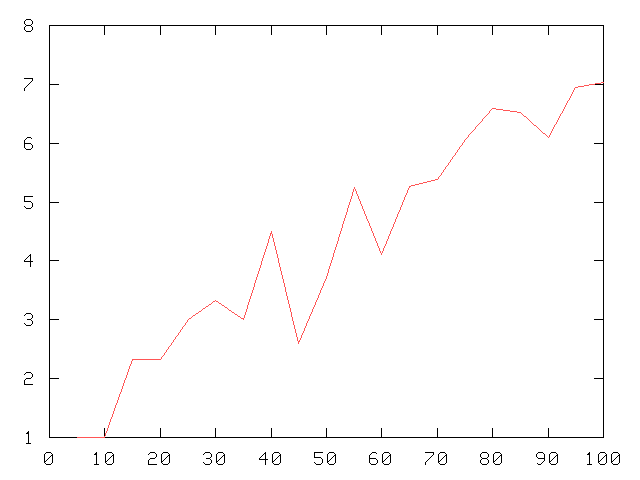
| Ici, on voit le nombre moyen d'attributs impliqués dans les règles augmenter jusqu'à un niveau de coupure 35 %, puis s'agiter violement entre 35 et 60 % et enfin reprendre sa croissance. |
Conclusion sur les théories apprises hors zone grise
On apprend des théories plus simples, lorsque l'on se place hors zone grise. La coupure la plus naturelle se trouvant aux alentours des 60 % (dans la suite, on sera donc particulièrement attentif aux tests réalisés à ce niveau de coupure).
Outre l'aspect des théories, il faut maintenant discuter de leur pouvoir prédictif.
Test de l'hypothèse de François
Motivation
Il s'agit de confirmer que les prédictions sont meilleures lorsque l'on apprend et que l'on teste hors zone grise. Il nous faut également déterminer si une théorie apprise sur des données propres a de bons résultats prédictifs sur des données non nettoyées (hypothèse dite de François).Protocole
L'idée est d'apprendre sur des données propres en fonction d'un paramètre de coupure, puis de s'évaluer sur deux ensembles test :
- des données propres écartées lors de l'apprentissage ;
- ce premier ensemble auquel on ajoute les exemples gris exclus.
Par ailleurs, on réalise un autre apprentissage sur des données non nettoyées comportant le même nombre d'exemples que les données nettoyées utilisées ci-dessus ; cet apprentissage est évalué sur les exemples restant, donc non propres.
Pour tous les apprentissages suivants, la redondance était réglée à 15 et les essais_nettoyage à 500, les résultats présentés maintenant sont la moyenne obtenue sur 15 apprentissages.
Résultats
| 5 % | 10 % | 15 % | 20 % | 25 % | 30 % | 35 % | 40 % | 45 % | 50 % |
| 55 % | 60 % | 65 % | 70 % | 75 % | 80 % | 85 % | 90 % | 95 % |
Avec le même nombre d'exemples dans chaque ensemble d'apprentissage, on apprend systématiquement moins de règles, chacune faisant appel à moins d'attributs, sur les données nettoyées.
|
On observe également un meilleur pouvoir prédictif sur l'ensemble de test pur (cela est indiscutable même si cela se dégrade au fur et à mesure de l'arrivée des exemples). Par contre, sur l'ensemble de test bruité, les performances sont incomparables du point de vue de la courbe ROC. |
La question de l'hypothèse de François reste donc ouverte.
Caractérisation de la zone grise
Protocole
On isole les exemples EVENT considérés comme gris suivant le point de coupure et on essaye de les caractériser contre les EVENT écartés (donc propres), puis dans un second apprentissage, contre l'ensemble (EVENT et NO EVENT) des exemples propres.
Pour tous les apprentissages suivants, la redondance était réglée à 80 et les essais_nettoyage à 1000.
Caractérisation des EVENT gris contre les EVENT blancs
| 5 % | 10 % | 15 % | 20 % | 25 % | 30 % | 35 % | 40 % | 45 % | 50 % |
| 55 % | 60 % | 65 % | 70 % | 75 % | 80 % | 85 % | 90 % | 95 % |
En opposant EVENT gris et EVENT blancs, on retrouve naturellement des caractérisations de personnes saines et sans risque. Par exemple, la règle suivante caractérise la majorité des EVENT gris pour une coupure à 55 % :
Sexe vaut Female Taille est entre 147.32 et 167.64 Diabète vaut NO Infarctus du myocarde vaut NO Accident vasculaire cérébral vaut NO Tabagisme vaut NOT SMOKER |
Ce qui est bien le profil typique d'une personne sans risque : femme, plutôt grande, ne fumant pas, sans diabète et sans antécédent.
Caractérisation des EVENT gris contre tous les blancs
| 5 % | 10 % | 15 % | 20 % | 25 % | 30 % | 35 % | 40 % | 45 % | 50 % |
| 55 % | 60 % | 65 % | 70 % | 75 % | 80 % | 85 % | 90 % | 95 % |
On retrouve ici la même difficulté que lorque l'on travaille sur la totalité des exemples : les EVENT gris ne sont pas facilement séparables des NO EVENT propres, et les théories explosent donc en une myriade de règles extrêmement complexes et spécialisées.
Discussion sur la caractérisation de la zone grise
Il apparaît que la caractérisation de la zone grise n'a que peu d'intérêt : soit les règles découvertes sont évidentes et prévisibles, soit elles nous replongent dans les mêmes difficultés que celles rencontrées sur l'ensemble des données.
Seule la connaissance de la classe nous permet de détecter les gris, il n'y a donc pas d'utilisation possible en prédiction.
En conclusion (provisoire), il y a bien une variable latente, elle nous manque, mais il n'y pas moyen de retrouver cette connaissance à partir des informations dont nous disposons.
Tests de calibrage des scores
Objectif et méthodologie du calibrage
Il s'agit en quelque sorte de vérifier qu'un score se comporte comme attendu : grossièrement, on va tester si le nombre de malades déclarés augmentent bien avec la mesure de risque.
Dans ce qui suit, les scores ont été découpés en 7 tranches égales (nombre de tranches arbitraire) et on a mesuré le taux de EVENT dans chaque tranche. Il semble que ce ne soit pas tout à fait la procédure habituelle qui consiste à découper en tranches regroupant le même nombre de personnes (à discuter avec François).
Score de Pocock
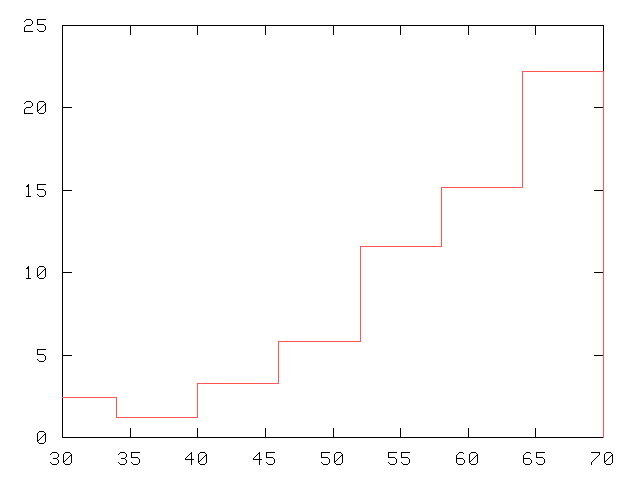
|
On observe pour le Pocock une jolie progression en escalier, un bon calibrage donc. |
Fabien (août 2002)
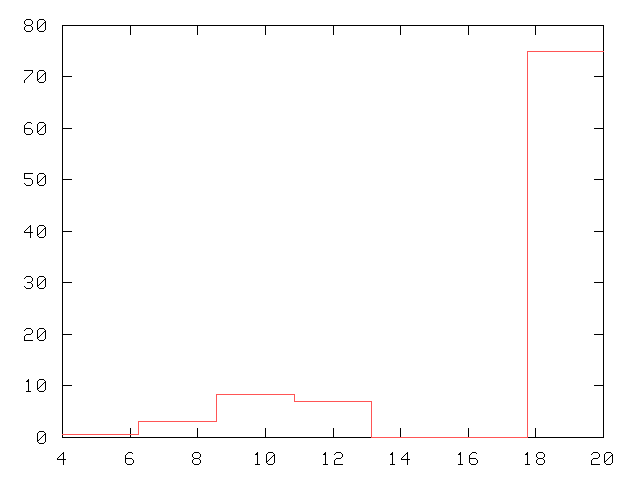
|
Un fort taux de EVENT dans la dernière tranche mais pas de profil en escalier. |
Utilisation des scores en prédiction
Principe
On pose une borne sur le score, les patients ayant un score inférieur à cette borne sont classés en NO EVENT, ce qui sont au-dessus en EVENT.
La borne étant difficile à régler, on la fait varier et, pour chaque valeur, on évalue le classifieur obtenu. Finalement, on trace une coube ROC pour chaque valeur du point de coupure.
Application aux scores Pocock et Fabien (août 2002)
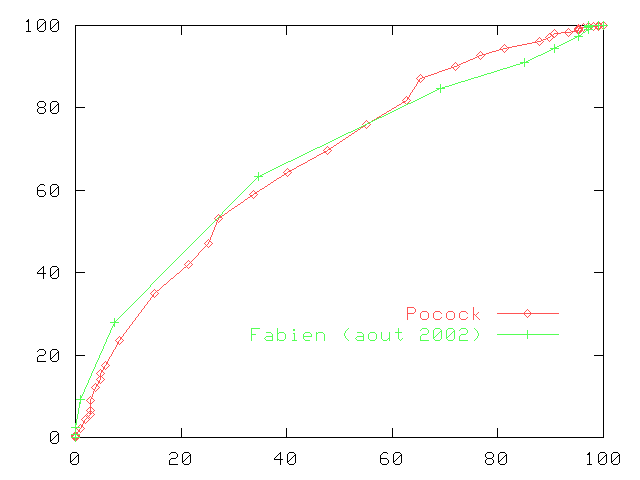
|
On voit qu'un mauvais calibrage, comme pour Fabien (août-2002), provoque des no man's land le long de la courbe ROC. Autrement dit, il y a des zones de performance pour lesquelles nous n'avons pas de classifieur à proposer. Cependant, on voit que le score Fabien (août 2002) se comporte honorablement et même mieux que Pocock sur certaine portion de la courbe ROC. |
Cela dit, il faut relativiser ces bons résultats par le fait que le score Fabien (août 2002) a été défini par l'observation de ces mêmes données qui nous servent de test.
Utilisation de GloBo pour produire des scores de risque
Principe
On produit des règles à la manière de GloBo mais sans effectuer ensuite de sélection parmi elles. On garde ainsi un grand nombre de règles et le score de risque d'un exemple est alors le nombre de règles qu'il active.
Pour tous les apprentissages suivants, la redondance était réglée à 50 et les essais_nettoyage à 10.
Résultats
| 5 % | 10 % | 15 % | 20 % | 25 % | 30 % | 35 % | 40 % | 45 % | 50 % |
| 55 % | 60 % | 65 % | 70 % | 75 % | 80 % | 85 % | 90 % | 95 % | 100 % |
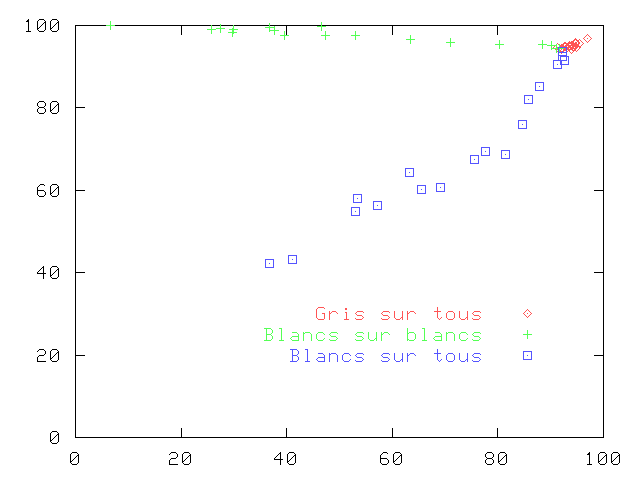
Les résultats sont encourageants comme le montre les extraits de courbe ROC ci-dessous. À nouveau, il faut relativiser les résultats par le fait que les mêmes données servent à la fois à l'apprentissage et au test. Autre restriction, nous avons utilisé Pocock pour nettoyer les données.
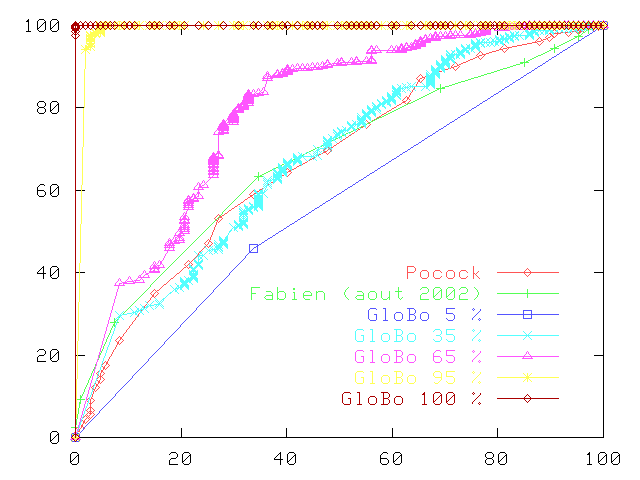
|
En particulier, les tests à un niveau de coupure de 100 % correspondent à un sur-apprentissage où le bruit a été appris. On peut tout de même se sentir encouragé par le fait que les courbes des niveaux de coupure autour de 60 % (limite estimée de la zone grise) sont meilleures que celle de Pocock. |
Conclusion sur l'utilisation de GloBo pour produire un score
Il est possible de restreindre le nombre de règles (utilisation habituelle de GloBo) et d'associer à chaque règle un poids correspondant au nombre d'exemples couverts par la règle dans l'ensemble d'apprentissage (ce qui revient strictement au même que la procédure décrite plus haut). Ainsi, nous pouvons disposer à la fois d'une théorie et d'un score.
Notre opération est assimilable à un boosting du score de Pocock, un bootstrap en quelque sorte. Ce boosting peut potentiellement être itéré, et être généralisé à un score quelconque.
Bilan et perspectives
- Il n'y a pas, a priori, de caractérisation accessible de la zone grise.
- Il faudra étudier la possibilité d'avoir des points de coupure différents dans chaque classe.
- L'apprentissage d'un score avec GloBo est viable, il reste à se dispenser de l'utilisation du score de Pocock, une possibilité étant d'apprendre des règles sur chaque classe.
- Il nous faut de nouvelles données pour le test.
Retour au projet INDANA.